


ChainLPはNo.722さんが無料で配布している、小説やコミックの電子化(自炊)ソフトウェアです。
このページではインストールから使用方法までをまとめています。
詳しいことは作者のブログを見ていただきたいのですが、実際に使ってみるとよく分からないことがいっぱいあります。
このソフトウェア名称「ChainLP」でググった回数は数え切れません。
よく知らなくても使えます。しかし、試行錯誤の中で得た、独自のノウハウもあるかもしれないので、私がこのソフトウェアをどのように使っているかを、楽天koboの電子書籍リーダーへの最適化事例で分かりやすく紹介します。
もちろん、同様の方法でKindle Paperwhiteへのデータを作ることも可能です。
電子書籍リーダー毎の解像度の違いだけです。
※私はMacユーザーなので、Parallelsを使用してWindows7上で使っています。
ChainLPが出来ること
- スキャンしたpdf、jpg(png)画像を様々な書籍リーダーに最適化した電子書籍データを出力してくれる
- 書籍リーダーは6インチ画面のものが主流なので、書籍の余白部分を削除して見やすくしてくれる(ノンブルやページタイトルも削除してくれる)
- 傾いてスキャンされたページを補正してくれる
- 薄くスキャンされたページも濃くしてくれる
最初のステップ:ChainLPのインストール
- No.722さんのHPからダウンロードしパソコンの好きな場所におく(私はドキュメントの中に入れてある)
- ランタイムのインストール(Microsoft.Net framework 4.0というランタイムがないと動きません。ランタイムはこちら)
このランタイムは既にインストールされている場合もあるので、ChainLPを起動してみてメッセージが出たらインストールすればよい。 - ePub作成のためにzip32j.dllとzip32.dllが必要(こちらからダウンロード)。ダウンロードしたら、システムフォルダーにコピーする。
この2つは32bitパソコンと64bitパソコンでコピーする場所が違うので注意が必要。
●32bitパソコン:systemフォルダーの中
●64bitパソコン:SysWOW64フォルダーの中 - Kindlegenをダウンロードし解凍。その中のKindlegen.exeをChainLPフォルダーの中に入れる。
※ダウンロード方法の詳細は以下の「Kindlegenについて」を参照してください。
- 簡単PDFダイエット(20131005-PDFDiet-release)をダウンロードして解凍(ダウンロードはこちら)
- 20131005-PDFDiet-releaseを任意のフォルダーにコピー(私はドキュメントの中に入れてある)
- kindlestrip_multi_batchをダウンロードし解凍。(ダウンロードはこちら)
- kindlestrip_multi_batchを解凍して20131005-PDFDiet-releaseの中にコピー
- kindlestrip_multi_mobiのエイリアスを作ってデスクトップに配置
※1〜4まででKindle用のMobiデータをサイズダウンしない場合はインストール完了です。サイズダウンしなくてもKindleで電子書籍を読むことは出来ます。
※5〜9についてはkindlestrip_multi_batchがダウンロード出来た場合に行ってください。kindlestrip_multi_batchはしばらくの間ダウンロード出来るURLが無くなっていました。
※もし、またkindlestrip_multi_batchが手に入らなくなった場合、Kindle用のMobiデータのサイズダウン方法の代替案を別ページにしました。以下をご参照ください。

Kindlegenについて
※4 Kindlegenもダウンロード出来なくなっていますが、ページ下のリンクをたどれば、ダウンロード出来るページに転送されます。
一応ダウンロードアドレスを記載しておきます。

ページの「Downloads」から、KindlePreviewerInstallerをダウンロードしてください。解凍するとフォルダーの中にKindlegen.exeが入っています。
但し、このバージョンは64bit OSです。
32bit OSの場合は以下のアドレスからダウンロードしてください。
※2023.5現在ダウンロード可能
Acrobat Proでjpgファイルのフォルダを用意
前回の記事でjpgのトリミングを紹介しましたが、その方法でjpgフォルダを作成。
ChainLPはpdfのままでも読み込み可能なのだが、前回記事で紹介したようにトリミングしないと、余白を上手く圧縮できない場合があります。
ChainLPでも入力事前トリミング機能があるので、Acrobat Proが無くても大丈夫です。
ChainLPのみでスキャンデータpdfから電子書籍を出力する方法は以下を参照してください。

ChaimLPを起動しjpgフォルダを読み込む
前回も紹介した田中芳樹のタイタニア5をサンプルにデータを読み込んでみる。
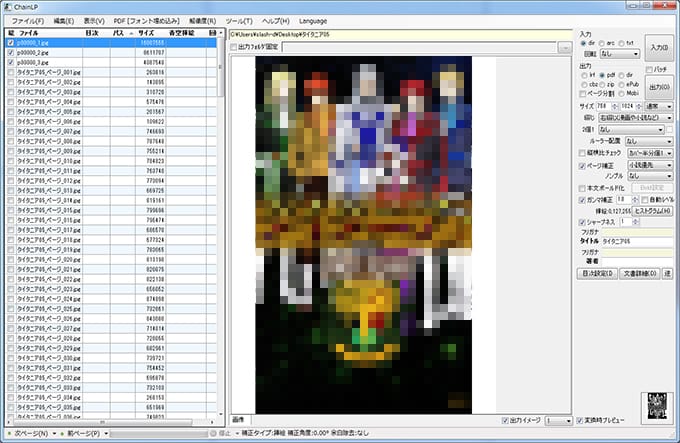
読み込み完了すると以下の様になる。
ChaimLPの設定をkobo aura h2o用に設定し、データ出力
様々な設定がありますが、今回はとりあえずkobo用のデータが出来るように設定します。
(設定のバリエーションに関しては別記事で紹介する予定です。)
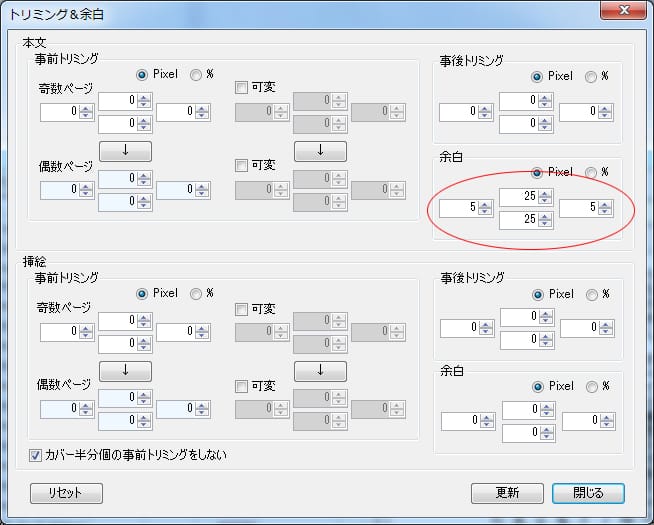
まず、koboで見た際の余白を設定します。
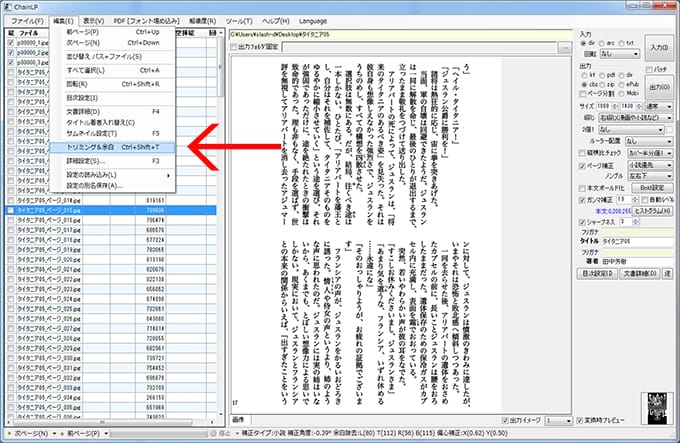
私の場合、上下25ピクセル・左右5ピクセルの余白を設定しています。
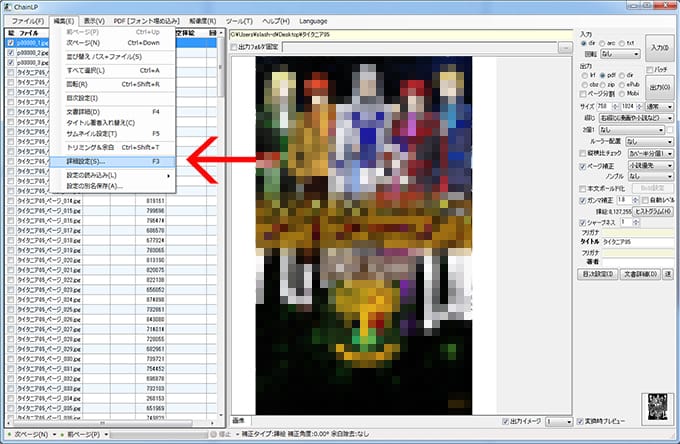
次に詳細設定を行います。
koboは文字がかすれやすいため文字を濃くしています。
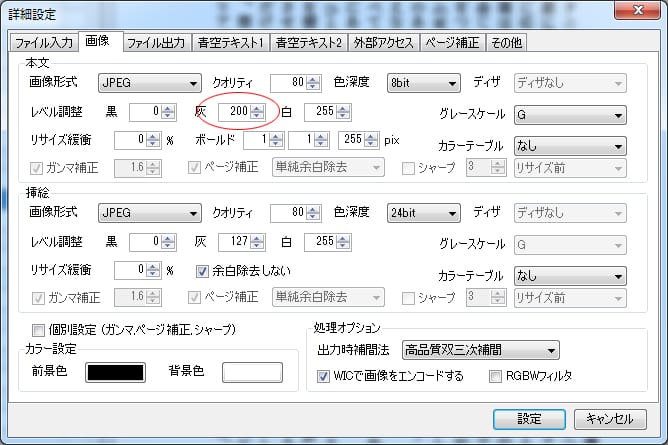
除去リミットを調整して好みの大きさにします。
ここはどんなにググっても分からなかったのですが、
除去リミットを調整することで文字が少ないページも文字の多いページと同じような圧縮率に処理することが出来ます。
文章が少ししか入っていないページが極端に大きな文字になることを抑えられます(※重要です)。
パーセンテージは試行錯誤で調整してください。
ノンブル転送して左右下に配置するようにしています。
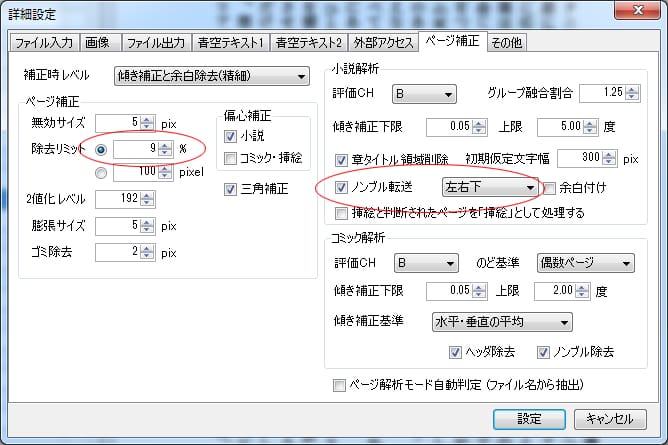
①koboデータはcbz
②kobo aura h2oの解像度は1080×1430ピクセル1080×1429ピクセル(※縦1429ピクセルが正しいことが分かりました。)
③この本はノンブルが左右下にあるので「左右下」を設定します。
④好みの濃さになるようにガンマとシャープネスを調整します。
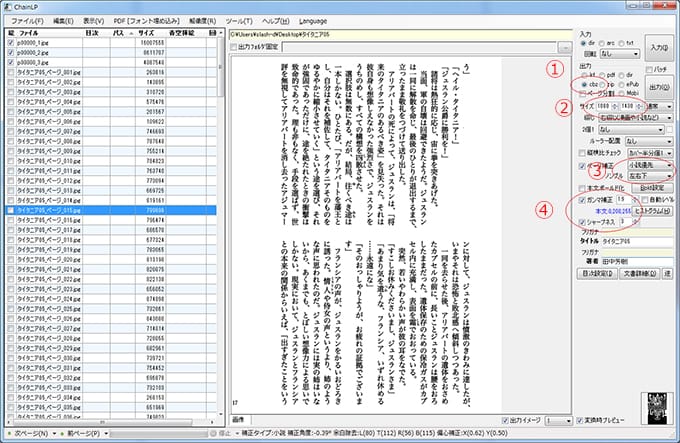
後は「出力」 ボタンを押してデータが出来るのを待つだけです。
出力データと元データの比較
元のデータ

処理後のデータは余白が除去され、ノンブルの位置が変わっています。

これで後はkobo aura h2oに転送して読むだけになりました。
電子書籍端末の最適化データを作成する
KindleやKoboに最適化した電子書籍データを作るためには以下のページも参考にしてください。


電子化ノウハウのまとめページを作りました。


© bluelady.jp

コメント
大変参考になる記事をありがとうございます。
ご質問があります。
Kindlegen.exeをChainLPフォルダーの中に入れたのですが、ChainLPを起動し、出力時に「Kindlegenがフォルダにありません」とメッセージが出て、中断してしまいます。もし原因などご存知でしたら教えていただけないでしょうか?よろしくお願いいたします。
ryomaさま、書き込みありがとうございます。
私のChainLPフォルダーを確認してみましたが、Kindlegen.exeはChainLPのフォルダーに入れるだけです。
1〜4までのインストールが間違いなければ動くはずなんですが…
もう一度最初からインストールしてみるぐらいしか、ご助言のしようがありません。
お力になれず、申し訳ないです。
ryomaさん、当方でも最初からインストールしてやってみました。
問題無くKindleデータを作ることが出来ました。
当方の環境はWindows7でKindle Paperwhite用のデータを作ってみました。
久しぶりなのでzip32j.dllとzip32.dllのダウンロードに迷ってしまいましたが、どちらも上から2番目のダウンロードリンクでダウンロード出来ます。(Kindleデータには必要ないですが…)
やっぱりお力になれず、すみません。
こんにちは。
電子書籍端末を買ってから,自炊本の電子書籍化についていつも参考にさせていただいています。
Linさんにはとても感謝しています。
というより,このサイトがあったから端末を買って自炊化を決めたほどです。笑
質問があるのですがよろしいですか?
KindlePWからKoboFormaに乗り換え,大きい画面で自炊本を快適に読もうと思っているのですが,KoboForma用で読むEpubファイルサイズは全て100MBを超えてしまいます。
KindlePWの時は,PDF2IMGーChinLP(PDFで出力)ーPDFDietEasy(Mobi出力)と最終的にサイズをある程度小さく出来たのですが,
KoboだとPDFDietEasyでサイズを小さくしようと思っても,そもそも出力サイズにKoboForma用がありません。(NewIpadなどはあるが。。)
そこで,どうやってファイルサイズを小さくしようとネットで調べてみても,PDFのサイズを縮小する方法はあってもEpubにはありません。
そこで伺いたいのは,
1,KoboFormaで(OCR化されていない)自炊本を読む場合,PDFよりEpubの方が良いのでしょうか?
2,仮にEpubの方が良いという場合,ファイルサイズを小さくする方法はありますか?
よろしくお願いします。
真理さん、どうもありがとうございます。
私のブログは私自身がいつもやっていることを書いているだけなので、実は詳しいことが分からない場合もありますし、書いた当時はいろいろと調べて分かっていても、忘れてしまうことが、多々あります。
そこで、現在私がお答えできる範囲で、お答えします。
少々、間違っているかもしれません。
まず、2番から
事例によって説明します。
私がKoboFormaで読んでいるのは小説の新書本のみです。
ある新書本をKoboForma対応で電子化してEpubを作成すると81.1MBのデータ量となりました。
そこで、今度は同じ新書本をKindle対応のMobiファイルにしてみました。
すると165.7MBになりました。
圧縮すると84.8MBとなり、KoboForma対応のEpubとほぼ同じになります。
結論から言うと私のページに紹介されている方法でKoboForma対応のEpupを作った場合、これ以上の圧縮は出来ません。
そもそもKidle対応のMobiファイルには画像が2つ分格納されているので(どうしてそのようになるのか忘れてしまいました)、それを1つにすることで半分のデータに圧縮することが出来ます。
また、PDFのデータについてはJPG画像の集まりなので、JPGデータの圧縮によってデータ量を抑えることが出来ます。
もし、KoboForma対応のデータを小さくしたいとすると、スキャンしたPDFファイルから画像を出力する際にクオリティーを下げてしまうしかないと思います。
ただ、画像自体が粗くなるので気持ちよく読める圧縮量を模索する必要がありそうです。
次に、1番です。
Koboで自炊データを読むためには実はEpubにしなくてもかまいません。
PDFはフル画面で読めなかったと記憶していますが、フル画面で読むためにはcbz形式でデータを作れば大丈夫です。
cbz形式は画像の集合体のようなものです。画像をzip圧縮したものと同じものです。
そのためcbzには著者の名前等を格納できません。
cbzをEpubに変換すれば著者名も格納できるようになります。
koboは著者名で分類する機能があってこそ分かりやすいので、私はEpubにするのがいいと思います。
また、Epubにする際に使う「RcKepub」や「AozoraMaxPlus」は画像を文章として扱う機能が備わっています。
そのために画面リフレッシュ間隔を設定で変更することができます。cbzはページをめくる毎に毎回リフレッシュするはずです。
以上のような理由で
1.KoboFormaで(OCR化されていない)自炊本を読む場合,PDFよりEpubの方が良い。(実はPDFをKoboFormaに送ったことがありません。試したのはcbzとEpubのみです。)
2.Epubの圧縮はPDFから画像を出力する時点で行っておく必要がある。(KoboFormaはフルHDより大きなサイズなのでコミックや、ページ数が多い小説は100MBを超えてしまうかもしれません。私のデータでも100MBを超えているものがあります。)
という回答になります。
但し、2についてはどれほど圧縮できるか分かりませんし、電子本のクオリティが下がる恐れがあります。(実はやったことありません)
これでよろしいでしょうか?
ひょっとすると分かりにくかったでしょうか?
かなり心配になりました。
私はデータが大きくなることは諦めています。
PCに電子書籍データをためておいて、読みたいものだけをkoboに送って読んでいます。参考まで。
今後ともよろしくお願いいたします。
真理さん、すみません。
KoboFormaにPDFを送ってみました。
きちんとフル画面になっていました。
それに著者も出てました。
ただ、画面リフレッシュが設定できません。
最初のページ送りで1回だけリフレッシュされただけです。その後はいつまでたってもリフレッシュしてくれません。
よってEpubにするメリットはリフレッシュ間隔を変更出来るという1点だけになります。
それとKindlePWの作り方は、私の場合ChinLPでMobi出力→Mobiをストリップ(不要な画像データを削除してデータ量を半分にします)
という流れなので、真理さんの方法と少し違っています。
さきほどの説明は上記のやり方を前提にして説明してしまいました。
かさねてお詫びします。
さらに不明点がある場合はお気軽にお書き込みください。
よろしくお願いします。
>Mobiをストリップ
そ,,そんな良い方法があったなんて。。笑
知らなかったです。
私もKindleのCloudに自炊本を保存させるためSendtoKindleのファイルサイズ上限50mbをなんとかクリアしようと悪戦苦闘してましたが。
まあ,それは置いといて。。
返信ありがとうございます。いろいろ勉強になります。
はい,私も今PDFをFormaに入れてみました。スワイプでの高速ページめくりも出来ないです。
PDF形式,あまり使えないみたいですね(気のせいか文字と挿絵も粗い様な。。)
私も同サイトの
をありがたく参考にさせてもらっています。
となると順序は,
1スキャンしたPDFー2PDF2Imageー3ChainLP(Zip出力)ー4AozoraEpub
ー5「RcKepub」か「AozoraMaxPlus」(画面リフレッシュを設定したいなら)。
ファイルサイズを小さくしたいなら3番目のChainLPをZip出力ではなくてPDFにして,その後に縮小,それからまたまたChainLpでZipに変換。。?(そうすればすでに綺麗に編集出来た内容のPDFを縮小できる?)
ごめんなさい,私も訳がわからなくなってきました。
LinさんはPDFDietEasyの他にPDFを縮小できるおすすめのソフトを知ってますか?
よろしくお願いします。
真理さん、おそらく今までやっていたKindleのデータを作成する方法で、1920×1440の大きさのPDFを作って下さい。(圧縮も慣れた方法で行えばいいのではないかと思います。)
それをChainLPで読み込ませて
の方法でForma対応のデータを作ればいいと思います。
参考になるのは以下のページです。
●PDFをChainLPで処理する(余白の設定等は無視して下さい)
●KoboForma対応の電子化
●Mobiデータを圧縮する
●その他電子化ノウハウのまとめ
ブログに少しずつ書いていたら、だんだん分かりにくくなってしまいました。
申し訳ないです。
私はPDFを縮小するとデータが読みにくくなりそうで、詳しくないです。
すみません。
>PDFを縮小できるおすすめのソフトを知ってますか?
すみません。
こちらで圧縮と縮小を間違えていました。
詳しい説明で大変勉強になりました。またこちらの勘違いも訂正できました。
>結論から言うと私のページに紹介されている方法でKoboForma対応のEpupを作った場合、これ以上の圧縮は出来ません。
最後に質問ですが,Linさんは自炊本をOCR化について検討したことはありますか?
以前私は,自炊本の文字をOCR化しようとChainLPで余白やノンプル,ゴミを消して文字を拡大し,文字認識を高めようとしたことがあるのですが(意味があったのか全くわかりません)。「読み取り革命」などのお試し版を使ってみても,多少の誤字がありましけれども,ファイルサイズはものすごい小さく出来ますよね。
真理さん、出来上がりのデータ量を減らす方法ですが、ChainLPやRcKepubには画像クオリティを変更する機能がありました。(朝起きたら思い出しました。)
●ChainLP
編集→詳細設定→画像
本文:クオリティ:80を変更
挿絵:クオリティ:80を変更
●RcKepub
編集→各種設定
画像加工時JPG品質(1〜100):80を変更
ChainLPの80を70にすると84.9MBのデータが71.6MBになりました。
ChainLPのNo.722さんやRcKepubのkb86さんは本当に優れた開発者さんですね。
ユーザーのやりたいことがだいたい機能として実装されています。
優れたアプリを無償で提供して頂けて、ありがたいです。
これらの値を設定して試行錯誤することで、読みやすさとデータ量のバランスをとって下さい。
>圧縮と縮小を間違えていました。
私も「圧縮」「縮小」を厳密な使い方をしていないかもしれません。
あまり意識していませんでした。
データ量を小さくするという意味で両方を使っているかもしれません。
>自炊本をOCR化について検討したことはありますか?
OCRについてですが、ChainLPの青空文庫の設定でサポートしているのではないかと思います。
やったことはないので詳しくありませんが、もともとテキストを入力する機能があります。
「青空文庫 ChainLP」で検索すると情報が得られると思います。
私はNo.722さんのソフトウェアを知った時、6インチの小さい電子書籍リーダーで本を読むためにMeTilTranを使って文字を大きくして並べ替えを行っていました。
しかし、あるとき、そんな加工されたページに違和感を持ちました。
私が読みたかったのは紙の本のままのレイアウトだったからです。
ノンブルや章を入れて電子化することで読みたかったのは「これだ!」ということになりました。
実は購入出来る電子書籍を読むことが好きではありません。
小さい頃から本の活字に馴染んでいるので、電子書籍に違和感があります。
そんな流れでOCR化を試みていません。
ただ、PDFの音声読み上げには興味があります。
真理さんの書き込みを頂く前、そのことを調べていました。
あまり時間が無かったのでチラッと調べただけですが…
仕事をしながらAudibleを試したことがあります。
これはきちんと声優が読み上げるのでよかったです。
しかし、PDFの読み上げには望むべくもありません。
当面は自炊データで読書していくことになりそうです。
>しかし、あるとき、そんな加工されたページに違和感を持ちました。
私が読みたかったのは紙の本のままのレイアウトだったからです。
ノンブルや章を入れて電子化することで読みたかったのは「これだ!」ということになりました。
なるほど。
紙の本を主体にするのと,電子書籍として利便性を求めるのでは,まったく変わってきますね。
私は,KindlePWで常にわからない単語を辞書として検索できること(特に外国語の勉強)に感動して電子書籍デビューしましたが,最近は電子書籍の内容さえファイルの一つでしか無いような,所謂昔味わった本の中に物語が生きているっといった感動が薄れてきているように感じます。慣れの問題なのかどうかわかりませんが。。
昔の小説は,読者が物理的な本を読んでいることを前提に物語が構成されているものも少ないですしね。(ミヒャエルエンデなどはわかりやすく笑)
一つ一つ丁寧に返信頂きありがとうございました。
No.722さんのソフトウェアは素人にはわからないことが多かったので,Linさんの解説はとてもありがたかったです。
これからもブログ作り頑張って下さい。
ありがとうございました。
今後とも、よろしくお願いします。
またまた失礼します。
いくつか質問があるのですがよろしいですか?
1,ChainLPで目次設定をするとなぜかファイルサイズが倍増します。もともとそういう仕様なのでしょうか?
2,すでにOCR化されているファイルをChainLPに入れるとOCRが消えてしまいます。
これまたなぜでしょう?(OCRデータを消さないまま余白除去などの加工のやり方はご存じですか?)
真理さん、ChainLPの深いところまで探求されてますね。
実は私はもくじ設定をやったことがありません。
また、OCRについても詳しくありません。
ですので、想像でお答えします。
1.についてですが、もくじの情報とリンク情報が通常データに追加されるはずですので、データ量は増えると思います。
ただし、倍増となると増えすぎるような気もします。仕様を理解していないので、何とも言えませんが…
2.についてです。
ChainLPは画像データで電子化するので、OCRの情報は無くなってしまうと思います。
以上、私の見解ですので、正しいかどうかは保証できません。
一応ご参考まで。
Linさん
お世話になっています。
わからないたびに質問して,ご迷惑おかけしてます。。
ネットなどを含め,自分なりに調べてはいるのですが。。
が,,やっぱりわかりません苦笑
ChainLPは素晴らしいのですが,設定が意味不明すぎて,いじりながら画面の変化を見るっていうとんでもない試行錯誤をしていて,これは探求といえるのかどうかあやしいですね。。
質問の答え,参考にさせていただいきます。
ありがとうございました。
ご遠慮無くお書き込みください。
ChainLPは色々な設定があるので私も試行錯誤が絶えません。
ChainLPの目次設定についてはあまり資料がありませんね。
これを設定する方が少ないのだと思います。
OCRについてはやはりデータが無くなっている報告がありました。
以下URL
https://blogs.yahoo.co.jp/alpha3166/8719658.html
たしかに画像で補正作業を行うのでOCRデータは無くなってしまうと考えた方が良さそうです。
こんにちはLinさん,お世話になっています。
スキャン済みの本の中には,ページ周辺が汚れていることがありますよね。
エッジ部分の汚れです。特に白黒二値でスキャンした場合などは酷いです。
これらをChainLPの設定,ページ補正(無効サイズOOpix)で汚れを落としつつ,かつ傾き修正をしようとするのですが,なぜか一部は傾いたまま。たぶん,エッジの汚れが完全に取れていないのでしょうね。
そこで,etiltranを使って傾き補正をした後に,(傾き補正をしない設定で)ChainLPでエッジを綺麗にしようと思うのですが,このetiltranの変換後のファイルサイズ,ものすごく大きくなりませんか??
私の場合,約10倍近くになります。そもそもEtiltranの変換設定で,リサイズ無し,にしているのになぜなのか。。
ページのエッジを綺麗にしつつ,傾きもしっかり補正できる,そのような方法をご存じでしょうか?
ChainLPでページを綺麗にするため,「トリミング&余白」/「ゴミ除去」/「無効サイズ」を使っているのですが,うまく綺麗に設定できたと思うとどこかのページで文字が欠けている/ものすごい傾いている,なかなか上手く行きませんね。
真理 さん、こんにちは。
これは再スキャン出来ないという条件で考えるということですね。
etiltranの出力設定でクオリティが100になっていないでしょうか?
80でだいたい同サイズになるはずです。
また、出力する大きさに合わせて(縦か横かで短くならないように)リサイズすればいいと思います。
ChainLPで端が欠ける場合は膨張サイズを調整してみて下さい。
その他の方法としてはMeTilTranを使ってみるのも面白いかも知れません。
ページを画像扱いにしてやれば出来るかも。
私は文字を組み替えて同じようなことをやってみたことがあります。
MeTilTranでレイアウトするのは設定が難しいですけれど、見た目をあまりこだわらなければ問題無く読めるものが出来上がります。
でも一番いいのは明るく補正またはコントラストを高くしてスキャンしなおすことをおすすめします。
返事ありがとうございます。
設定はこちらのLinさんの
で設定しています。(「出力画像フォルダ分類」のチェックははずしています)
クオリティも80になっています。
もしかしたら元二値化画像,つまり1ビットのものをJPEGに変換してしまうからでしょうか。
>ChainLPで端が欠ける場合は膨張サイズを調整してみて下さい。
そうですね,これがありましたね!!ありがとうございます。
もう一つ気になっていたのですが,
このetiltran,バッチ機能あるのですか?
Linさんの
には無くて
にはあるのですが,これはWindowsのOSの関係ですか?
私のにはこのバッチ変換が無くて。
あ,ちなみに私はスキャナーを持っていなくて,レンタルでしたのでやり直しは再レンタルしないと出来ません^^:
真理さん、二値化画像はJPEGではないのですか?
一応フォトショップで2値化してテストしようとしたのですが、JPEGにすると変わらないですね。
……
あとバッチ機能については使用したことが無いので分かりません。
現状Windows10を使用しているのですが、バッチボタンが無いです。
にバッチ登録ボタンがあるのは何故か、私にも分からなくなってしまいました。
すみません。
>真理さん、二値化画像はJPEGではないのですか?
TIFイメージってありますね。
スキャンしたPDFをPDF2Imageに入れて,連番ファイルにしてからChainlpやEtiltranで使っているのですが,もしやこれが原因でしょうか。。
真理さん、やっとテストして見ました。(愛犬が病気でバタバタしてました)
確かにTIFを変換すると2倍以上の大きさになります。
どうしてこのようなことになるのか不明です。
Etiltranに読み込ませる前に何とかしてTIFをJPEGに変換すればいいのかもしれませんが、全てのページデータをひとつひとつ変換するのは無理があるかもしれません。